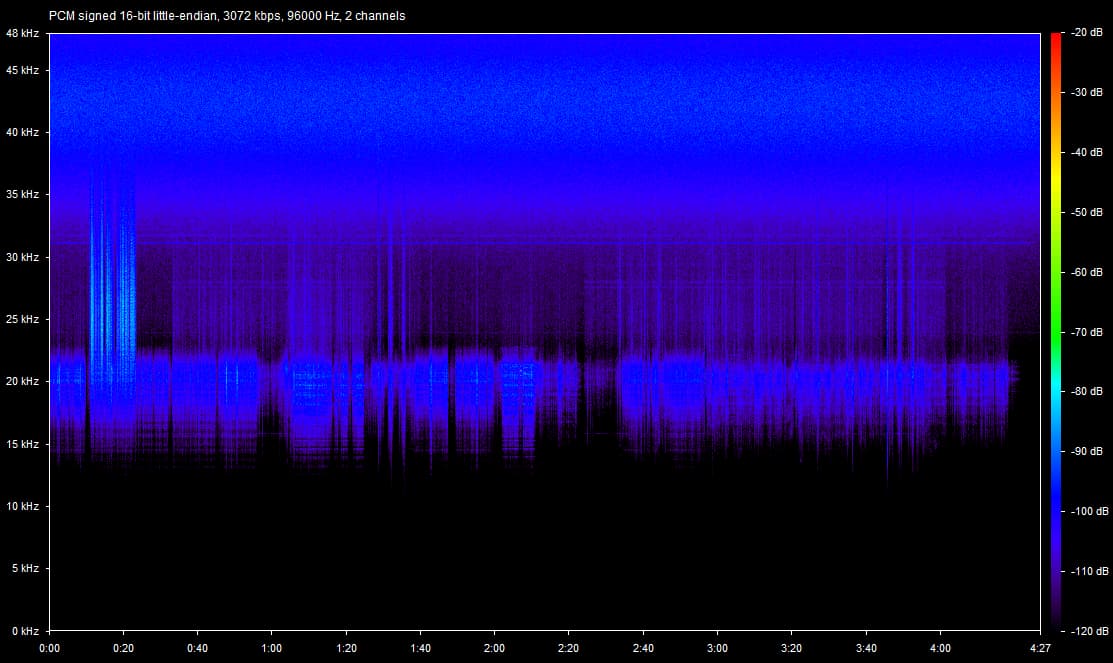
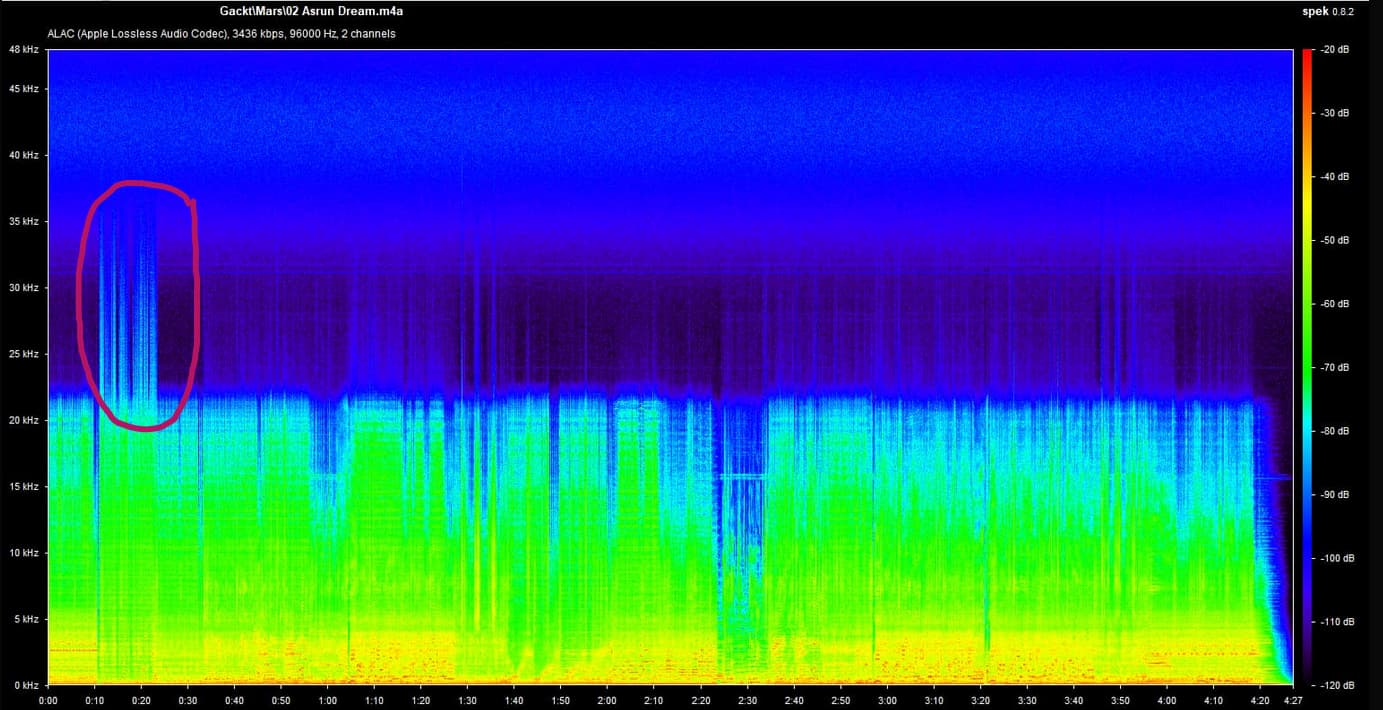
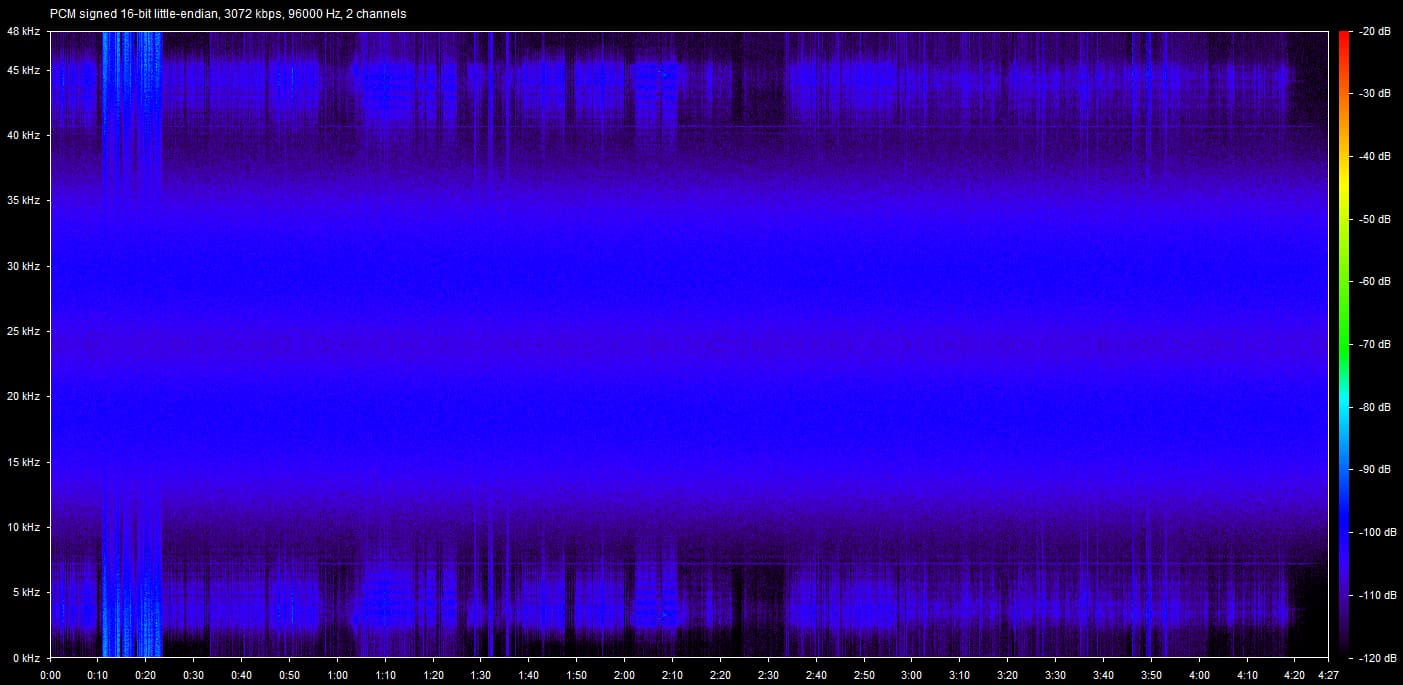
Venture no further if you don’t want to ruin music a little bit for yourself. Venture forward with no haste if you are interested in why I care about lossless files and bit-perfect reconstruction so much.
No seriously, I’m warning you. You sure you wanna know?
…you sure?
Okay.
There are a couple of tells in very low bit rate lossy audio files that make them stand out to me in comparison to a lossless file. I’m gonna go through a few of them here. If I missed any, feel free to add.
SHANNON-NYQUIST AND YOU
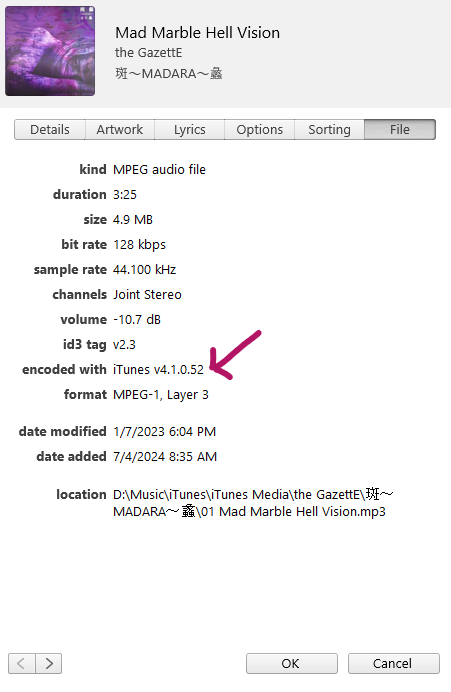
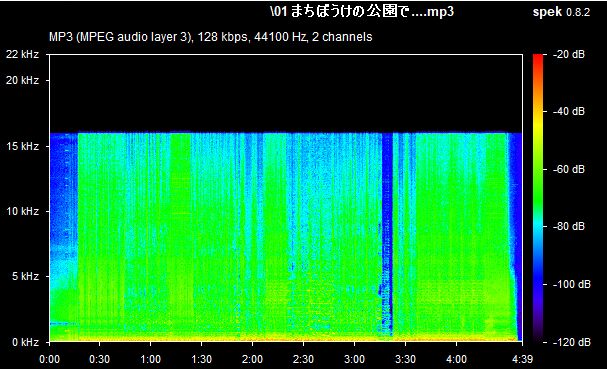
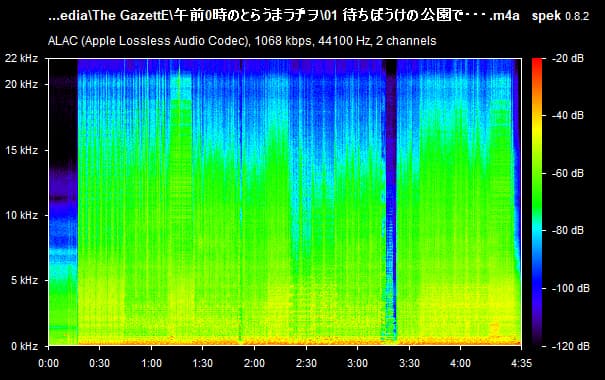
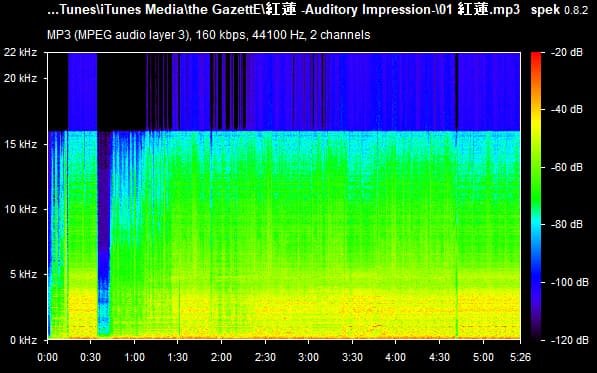
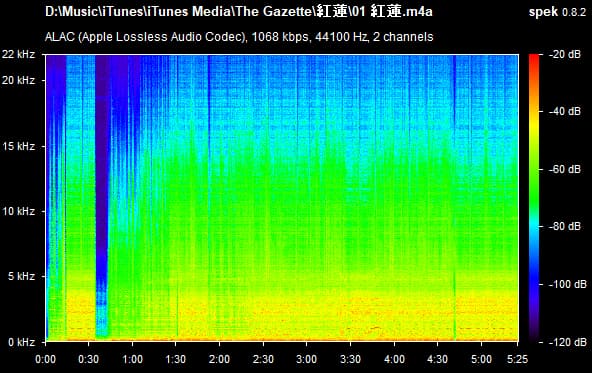
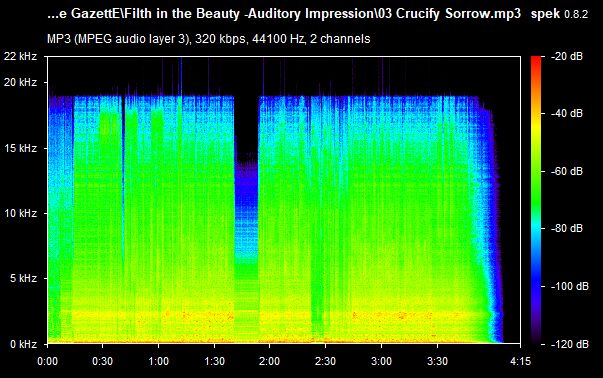
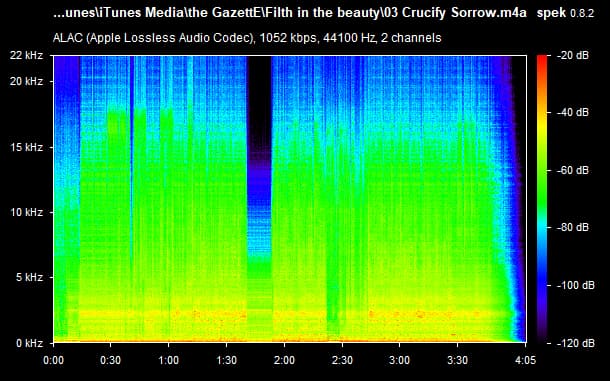
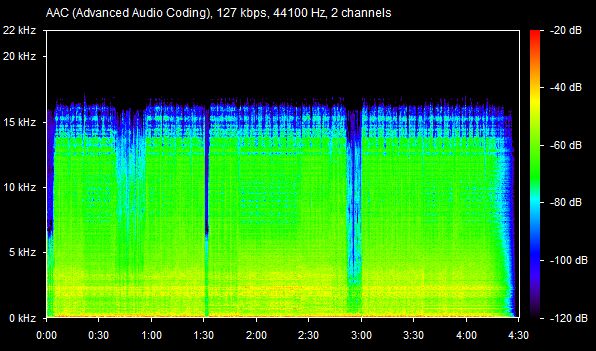
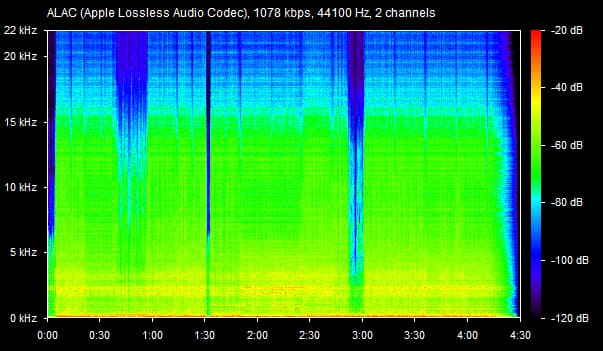
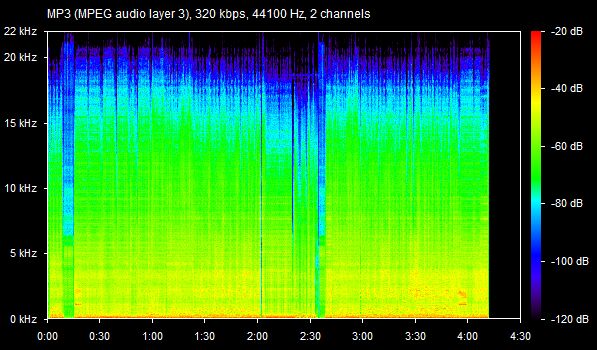
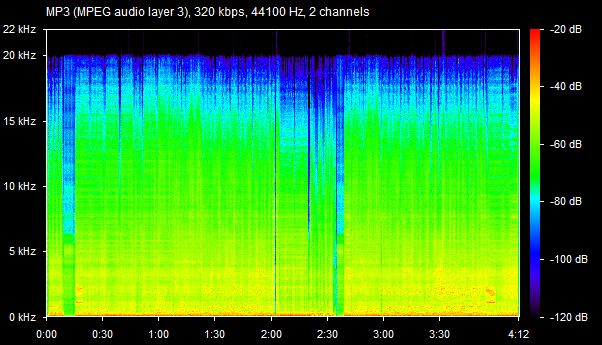
As we all know, lossy files are smaller than their lossless counterparts because the encoder uses an algorithm to literally truncate the higher frequencies. If you pull up a 128KBPS MP3 in a spectrogram analyzer, you can see that characteristic cut at 16kHz. In order to get an idea of how to accurately recreate the shape and amplitude of a frequency, the frequency must be sampled at twice the bandwidth of the signal. Or in other words, if you sample an analog signal at a rate that exceeds the signal’s highest frequency by at least a factor of two, the original analog signal can be perfectly recovered from the discrete values produced by sampling. If you do not do this, you get an unpleasant type of distortion known as aliasing. This is known as the Shannon-Nyquist theorem.
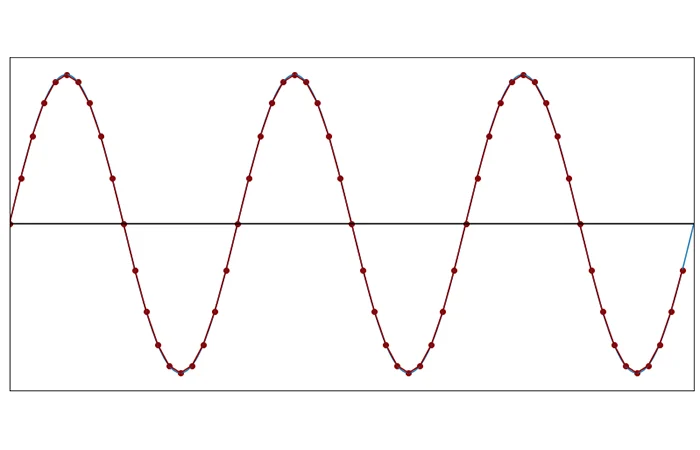
This is much easier to see with visuals. Here is a graph of a sound wave with each dot representing a sample.
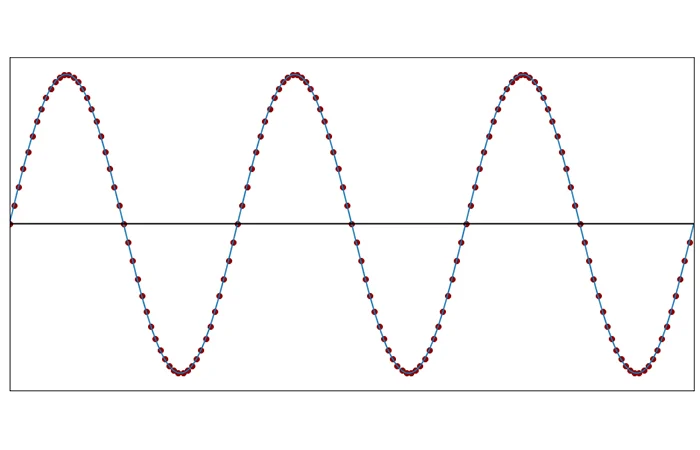
Here is that same wave, 20 samples a second:
Same wave once again, 10 samples a second. See how the wave starts to diverge from the original?
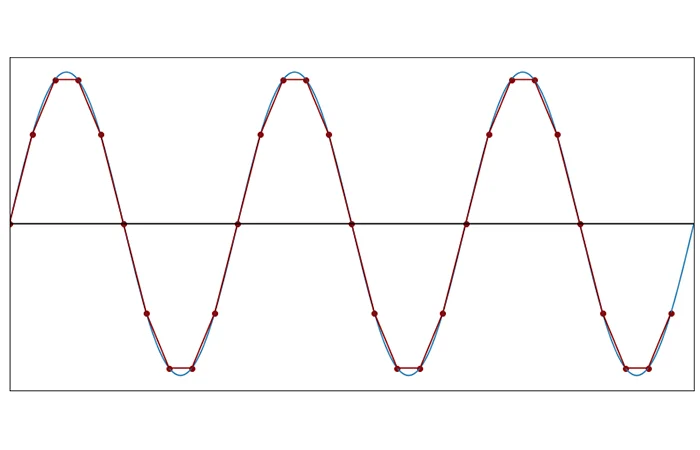
At 5 samples a second, it’s no longer a true representation of the original wave but all of the information is preserved.
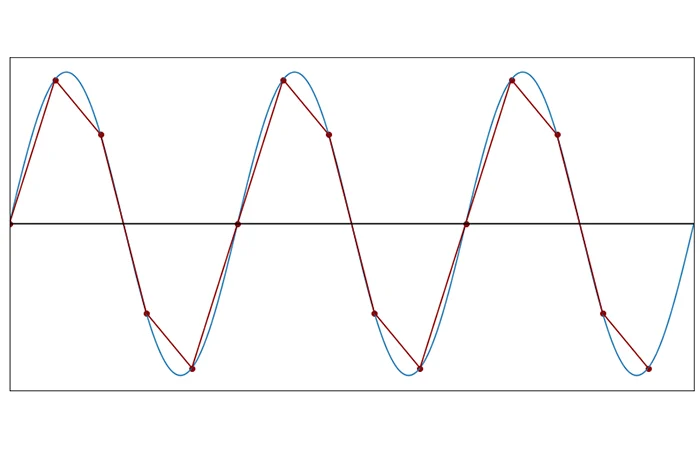
This is the absolute limit, which is two samples per cycle, which is what Shannon-Nyquist theorem says you need to reconstruct a signal.
This is what it looks like when you go less than two samples per cycle. This is 1.9 samples per cycle.
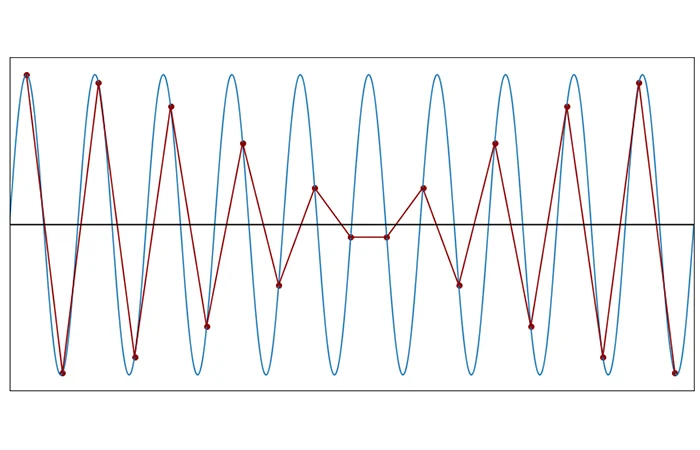
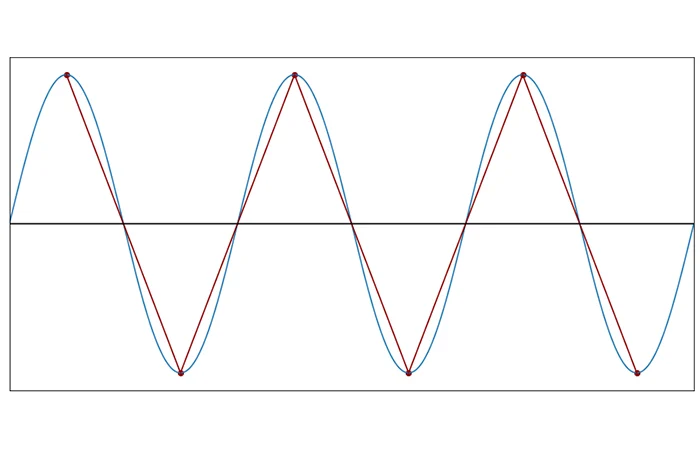
And this is 1.1:
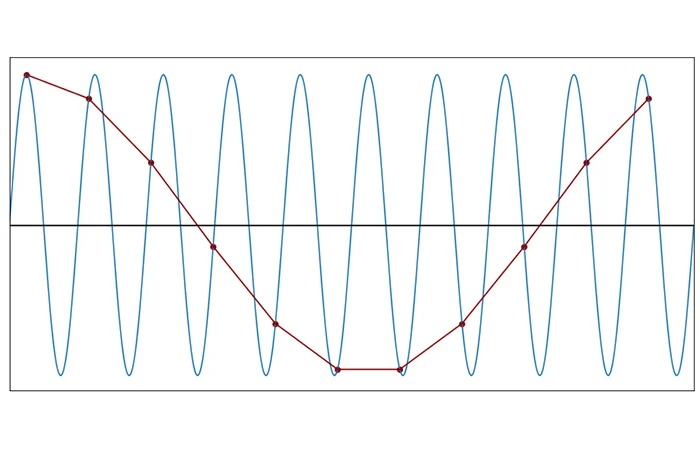
So you can see that the new wave constructed out of the samples is way different than the original wave and the original information cannot be reconstructed.
SHORTCOMINGS IN LOSSY FILES
Makes sense? Cool. I explained all of this because all the sampling required for perfect reconstruction take up a lot of space. The lossy encoder of your choice (we’ll use LAME as a stand-in) looks for ways to get rid of these extra bits without fundamentally altering the reconstruction of the signal. In fact, there’s several things going on:
The first one is that most sound above 20khz is completely removed. This is based on the idea that human hearing is unable to hear above that and any noise above that level would make the file size larger, since sounds above that region are much more complex to compress. Some people have reported being able to hear above 20kHz, so this is controversial.
The second part is psychoacoustics. The engineers that develop a lossy format create models of human hearing called psychoacoustics which show that many frequencies in a complex piece of sound become “masked” by other frequencies, and you more or less don’t hear them. To make the lossy file with a smaller footprint, many of these sounds are removed. The bit rate that you target determines the amount of this processing that’s applied - the lower the bit rate, the more processing done.
For example, a loud sonic event will mask a quieter one if they both occur within a small interval of time — even if the louder event actually occurs after the quieter one. The closer in time the potentially masked sound is to the louder, masker, sound event, the louder it needs to be in order to remain perceivable.
Research has shown that the human ear responds to frequency content using what are known as critical bands. These are narrow bandwidth divisions of the 20Hz-20kHz frequency spectrum. If a loud frequency component exists in one of these critical bands, that noise creates a masking threshold which will render quieter frequencies in the same critical band potentially imperceptible.
The last thing that’s done is that there are all sorts of mathematics involved in compressing data in which the reconstructed sound is close, but not quite the same as the input was. These processes have different effects, one of which causes a type of pre-echo that can cause some amount of smearing.
Pre-echo is a digital audio compression artifact where a sound is heard before it occurs. It is most noticeable in impulsive sounds from percussion instruments such as castanets or cymbals. The psychoacoustic component of the effect is that one hears only the echo preceding the transient, not the one following – because this latter is drowned out by the transient. Forward temporal masking is much stronger than backwards temporal masking, so it is easy to hear a pre-echo, but no post-echo.

Smearing in audio refers to a loss of clarity and definition in sound reproduction, often characterized by a blurring of transients and a lack of precision in imaging. This can result in a muddy or indistinct sound, making it difficult to discern individual elements in a mix.

Now let’s get into some ways that I can tell a lossy file is lossy.
CYMBALS SOUND LIKE BREAD
We just went into a lot of the reasons why above, but this is usually the dead give away. MP3 especially uses a compression algorithm that can sometimes introduce audible artifacts, particularly in the high-frequency range where cymbals and hi-hats reside, causing a slightly distorted or “harsh” sound. The lower the bit rate, the more harsh the artifacts.
The rapid attacks and decay of cymbal and hi-hat sounds can be smoothed out during MP3 encoding, resulting in a less defined and impactful sound. Something that I listen for is what I call the “wobble” of the cymbal, ride, or hi-hat, which I define as occasional peaks in an otherwise decaying signal. On the other hand, if you can make out the spin of a crash or ride as it’s happening, you know you’ve got a high quality file.
Along that same line…
DRUM HITS HAVE NO REVERB
There’s a subtle but definitely present amount of reverb that occurs when you’re listening to a drum set in real life. Some of it’s the room, some of it’s the instruments, some of it is perception. I don’t want drum kits to sound like I’m inside an oil canister, but I know I have a lossy file when the drums sound flat, as if every hit was sampled to be exactly the same.
If the drums sound flat and lifeless and my ear does not naturally gravitate towards it because it’s been de-emphasized in the mix, that’s one way I hear a poor quality drum sample. Drums should have body and slight variations from one strike to the next.
BASS SOUNDS FLUBBY
We talked a lot about what these encoders do to the high end, but what about the low end? This is truthfully an implementation detail, left to the various encoders, but any serious encoder throws out information under 20Hz, for the same reasons as I listed above (people are not supposed to be able to hear them). I personally can hear as low as 16Hz, so I also call this quite a controversial statement.
In general, low frequencies require much less information than high frequencies to encode. However, masked frequencies and silences are removed, amounting to a spectral ‘thinning’. This makes bass sound flubby to me when the encoder is really not up to the task, or when the file is of a sufficiently low bit rate.
HARMONIC DISTORTION
So, first of all, what is a harmonic?
If you take a note, like a C, and play it on a guitar or a piano, not only do you hear the note C, you also hear, very quietly, other notes that are mathematically related to that C. You might hear a C an octave higher, and then another octave above that, and you might hear an E and G mixed in there as well. It’s actually more complex than that, but the point is that if you play a note on virtually any instrument, you get more than the single note that defines the pitch. The other stuff are the harmonics.
The harmonics of an instrument are a huge factor in why it sounds the way it does. A guitar with steel strings has a different set of harmonics than a guitar with nylon strings. The steel string is typically brighter and more metallic, due to its harmonics!
Harmonic distortion is when harmonics are added to a sound, a signal, that aren’t there in the original signal. When it comes to the guitar, the complex body and physics of the instrument adds extra harmonics to whatever notes are being played, but this type of harmonic distortion is desirable.
Electronic components (amplifiers, etc.) also add harmonics to a signal. Usually a well-designed circuit adds a very, very tiny amount of harmonics. That is also harmonic distortion, but it’s imperceptible. A badly designed circuit can add enough harmonic distortion that one can really hear it. There are amounts of harmonic distortion that can be very noticeable, and certain patterns of harmonics are more noticeable. Some patterns sound good, and some sound bad.
Understanding the math of harmonics also explains why distortion seems to make something sound brighter: because what you’re adding is harmonics above the fundamental, and those harmonics stack up and increase the apparent high frequency tonality of a sound. This is why too much harmonic distortion can sound harsh and painful.
Lossy encoders remove a lot of harmonic information, which can make a song sound darker, hollow, and even quieter.
LESS SOUNDSTAGE
Soundstage is a subjective concept that refers to the spatial qualities of a headphone, such as the width, depth, height, and shape of the figurative space where parts of a song are placed. It’s also known as speaker image. The more realistic and nuanced the sound stage, the better the clarity and detail.
Lossy encoders shrink the sound stage. Sometimes it feels as if the “space” between instruments and layers in the mix is really small, or perhaps even absent. Ever listen to a deathcore track where the guitar and the bass are fighting for the same frequency bands, and everyone sounds “bunched” together? Lossy encoders definitely do not help in this aspect, because they throw out a lot of the information involved with precise placement.
Okay, I’m done spouting exposition. @rsm_rain I hope you’re proud.